散列表总结
本文整理自《算法导论》第11章,由于本章有一些概率论知识,因此理解起来比较困难,但是一般只要记住结果即可。
我在面试的时候也被问过:“请问哈希冲突的解决方法有哪些?”,这个问题的答案是:
第一种是链接技术,即用双向链表来链接哈希值相同的元素。这种方法能够有良好性能的前提是满足近似简单一致散列。
第二种是开放寻址法,而开放寻址法有几种生成探查寻列的方法,如线性探查、二次探查、二次哈希(double hashing),其中二次哈希用的最多。开放寻址法有良好性能的前提是满足一致散列。
(以上粗体字都是本文将要讲解的内容)
本文定义 n为实际要插入的关键字,m为槽的个数。
动态集合:支持插入、删除操作。
静态集合:只支持查找操作。
字典操作:
INSERT(T,x):将元素x插入T。
DELETE(T,x):将元素x从T中删除。
SEARCH(T,k):根据关键字k查找元素。
一、直接寻址法
定义:每个元素的关键字k就是数组的下标,比如一个元素的关键字为2,则T[2]就是元素存放的位置。被寻址的表称为直接寻址表。
前提:
(1)关键字的全域U较小,不然机器创建一个很大很大的数组不太可能。
(2)关键字都是自然数,不然不能直接寻址。
(3)没有两个元素的关键字相同,即不能“碰撞”。
优点:简单,方便。并且没有冲突。
缺点:
(1)关键字的全域很大时,如2^64,则计算机不能创建这么大的数组。
(2)如果关键字不是自然数,则不能直接寻址,比如关键字是string,则不能T[string]。
(3)如果实际使用的关键字只有少数,但是全域很大,则会造成空间的浪费。比如全域为100000,实际使用了2个关键字。
二、散列表
定义:设计一个哈希函数h,如果关键字为k,则h(k)就是哈希表下标位置。
优点:需要的空间少。
缺点:哈希冲突(书中称为“碰撞”)。
简单一致散列:如果任何一个关键字k,他映射到m个槽的任何一个的可能性都相同,并且k映射到哪个槽与其他关键字独立无关,则称为简单一致散列。
装载因子:n/m,即一个槽的链表的平均长度。
全域散列:任何一个哈希函数,都存在一个键集,使得他们映射到同一个槽中(即诱导发生最坏情况),因此全域散列就有用武之地了,他是预先定义一个有限的散列函数集(就是多个散列函数),等到真正开始执行时,随机选择一个散列函数(一旦开始执行,散列函数就不能改变),这样的优点是对手不知道你要选那个散列函数,看到的只是random()。
全域性质:从散列函数集中随机选择一个函数,两个关键字碰撞的概率至多1/m。
结论:
(1)在散列函数集是全域的条件下,成功查找的期望时间至多1+n/m。
(2)在散列函数集是全域的条件下,不成功查找的期望时间至多n/m。
证明结论:

选取散列函数是一门很大的学问,但是有一些启发式的函数,如:
1.除法散列法:h(k)= k mod m
注意点:
(1)m不能太小,m不能是2的幂次,m一定是质数。
(2)这个方法的优点是简单。
2.乘法散列法:h(k)=floor(m(kA mod 1)),这个方法一般比除法散列法好,因为乘法比除法快。
注意点:
(1)一般A=(根号5 – 1)/2
(2)一般m是2的幂次。
如果不理解乘法散列法,可以做做算法导论11.3-4。
完全散列:适用于静态集合(只有search操作),利用两级哈希,使得最坏情况下查找只需要O(1)。原理如下图:
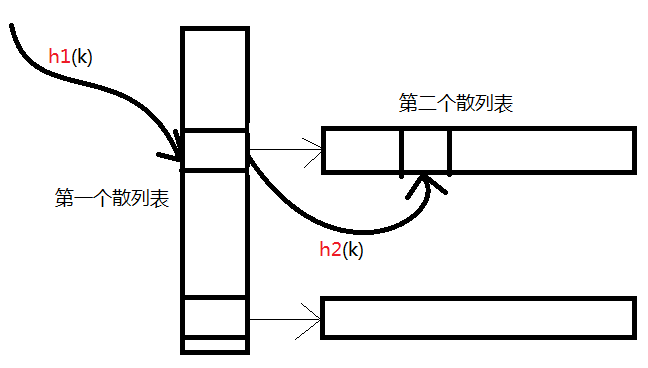
完全散列的要求:第二个散列函数必须是没有碰撞发生的。
三、解决碰撞的方法
有没有完全避免碰撞的方法呢?实际上是没有的,根据鸽巢原理,n只要大于m,一定至少有一个槽放了多于1个元素。
1、链接法
用双向链表来链接哈希值相同的元素。这种方法能够有良好性能的前提是满足近似简单一致散列。
简单一致散列:如果任何一个关键字k,他映射到m个槽的任何一个的可能性都相同,并且k映射到哪个槽与其他关键字独立无关,则称为简单一致散列。
结论:
INSERT操作的最坏情况时间为O(1)
DELETE操作的最坏情况时间为O(1)
查找不成功的SEARCH操作的期望运行时间为O(1+n/m),最坏情况时间为O(n),当n=O(m)时,期望时间为O(1)
查找成功的SEARCH操作的期望运行时间为O(1+n/m),最坏情况时间为O(n),当n=O(m)时,期望时间为O(1)
为了更好地理解链接法的随机性,可以做做算法导论11-2。
证明:简单一致散列的假设下,查找不成功的期望时间为O(1+n/m)
首先hash函数需要O(1),然后设Xk为T[k]的链表的期望长度,我们已知期望长度为n/m,查找不成功会遍历一个链表,因此查找不成功的期望时间为O(1+n/m)。
证明:简单一致散列的假设下,查找成功的期望时间为O(1+n/m)
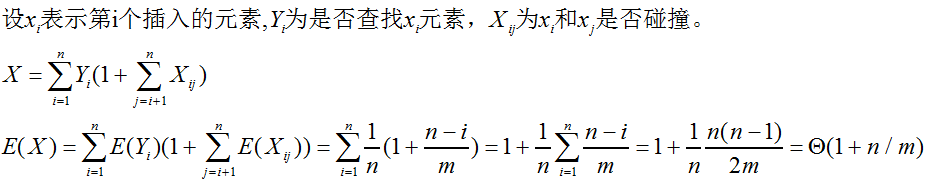
2、开放寻址法
开放寻址法是另一种解决碰撞的方法。
定义:将散列函数扩展定义成探查序列,即每个关键字有一个探查序列h(k,0)、h(k,1)、…、h(k,m-1),这个探查序列一定是0….m-1的一个排列(一定要包含散列表全部的下标,不然可能会发生虽然散列表没满,但是元素不能插入的情况),如果给定一个关键字k,首先会看h(k,0)是否为空,如果为空,则插入;如果不为空,则看h(k,1)是否为空,以此类推。
特点:散列表的每个槽只能放一个元素,因此当n==m时,最终会发生不能再插入元素的情况,n/m<=1。
一致散列:每个关键字所对应的探查序列是0…m-1的m!种排列的每个可能性都相同,并且和其他关键字独立无关。
开放寻址法好性能的前提是一致散列。
缺点:不支持删除操作,只支持INSERT、SEARCH操作,因此如果有删除操作,就用链接法。算法导论11.4-2要求实现DELETE操作。
生成探查序列的方法有:
(1)线性探查:h(k,i)=(h’(k)+i) mod m,可能有“一次群集”问题,即随着插入的元素越来越多,操作时间越来越慢。
(2)二次探查:h(k,i)=(h’(k)+ai+bi^2) mod m,可能有“二次群集”问题,即如果h(k1,0)=h(k2,0),则探查序列就一致。
(3)二次哈希:h(k,i)=(h1(k)+ih2(k)) mod m ,要求m和h2(k)互质,不然探查序列不能覆盖到整个下标。算法导论11.4-3证明了这点。
其中二次哈希最好,因为他能够生成m^2种(离m!最接近)排列,而线性探查、二次探查只能生成m种排列,而理想中如果满足一致散列的话,则会生成m!种排列。
结论:
(1)在一致散列的条件下,不成功查找的期望探查数至多为 1/(1-n/m)。
(2)在一致散列的条件下,成功查找的期望探查数至多为 1/(n/m) * ln(1/(1-n/m)),当然也可以至多为1/(1-n/m)[MIT开放课程中是这个,其实都差不多,下面我会证明]。
(3)在一致散列的条件下,插入的期望探查数至多为 1/(1-n/m)。
证明结论:
