抓图程序-Java grab 包的技术提示
几年前,我构建过一个基于命令行的
列表 4 GetImages.java
DE<// GetImages.java imp ort java.io.*; imp ort java.net.*; imp ort java.util.regex.*; imp ort javax.swing.text.*; imp ort javax.swing.text.html.*; imp ort javax.swing.text.html.parser.ParserDelegator; public class GetImages { public static void main (String [] args) { // Validate number of command-line arguments. if (args.length != 1) { System.err.println ("usage: java GetImages URL"); return; } // Create a Base URI from the solitary command-line argument. This URI // will be used in the handleSimpleTag() callback method to convert a // potentially relative URI in an tag's src attribute to an // absolute URI. final URI uriBase; try { uriBase = new URI (args [0]); } catch (URISyntaxException e) { System.err.println ("URI is improperly formed"); return; } // Convert the URI to a URL, so that the HTML document can be read and // parsed. URL url; try { url = new URL (args [0]); } catch (MalformedURLException e) { System.err.println ("URL is improperly formed"); return; } // Establish a callback whose handleSimpleTag() method is invoked for // each tag that does not have an end tag. The tag is an example. HTMLEditorKit.ParserCallback callback; callback = new HTMLEditorKit.ParserCallback () { public void handleSimpleTag (HTML.Tag tag, MutableAttributeSet aset, int pos) { // If an tag is encountered ... if (tag == HTML.Tag.IMG) { // Get the value of the src attribute. String src = (String) aset.getAttribute (HTML.Attribute.SRC); // Create a URI based on the src value, and then // resolve this potentially relative URI against // the document's base URI, to obtain an absolute // URI. URI uri = null; try { // Handle this situation: // // 1) http://www.javajeff.mb.ca // // There is no trailing forward slash. // // 2) common/logo.jpg // // There is no leading forward slash. // // 3) http://www.javajeff.mb.cacommon/logo.jpg // // The resolved URI is not valid. if (!uriBase.toString ().endsWith ("/") && !src.startsWith ("/")) src = "/" + src; uri = new URI (src); uri = uriBase.resolve (uri); System.out.println ("uri being " + "processed ... " + uri); } catch (URISyntaxException e) { System.err.println ("Bad URI"); return; } // Convert the URI to a URL so that its input // stream can be obtained. URL url = null; try { url = uri.toURL (); } catch (MalformedURLException e) { System.err.println ("Bad URL"); return; } // Open the URL's input stream. InputStream is; try { is = url.openStream (); } catch (IOException e) { System.err.println ("Unable to open input " + "stream"); return; } // Extract URL's file component and remove path // information -- on ly the filename and its // extension are wanted. String filename = url.getFile (); int i = filename.lastIndexOf ('/'); if (i != -1) filename = filename.substring (i+1); // Save image to file. saveImage (is, filename); } } }; // Read and parse HTML document. try { // Read HTML document via an input stream reader that assumes the // default character set for decoding bytes into characters. Reader reader = new InputStreamReader (url.openStream ()); // Establish a ParserDelegator whose parse() method causes the // document to be parsed. Various callback methods are called and // the document's character set is not ignored. The parse() method // throws a ChangedCharSetException if it encounters a tag // with a charset attribute that specifies a character set other // than the default. new ParserDelegator ().parse (reader, callback, false); } catch (ChangedCharSetException e) { // Reparse the entire file using the specified charset. A regexp // pattern is specified to extract the charset name. String csspec = e.getCharSetSpec (); Pattern p = Pattern.compile ("charset=\"?(.+)\"?\\s*;?", Pattern.CASE_INSENSITIVE); Matcher m = p.matcher (csspec); String charset = m.find () ? m.group (1) : "ISO-8859-1"; // Read and parse HTML document using appropriate character set. try { // Read HTML document via an input stream reader that uses the // specified character set to decode bytes into characters. Reader reader; reader = new InputStreamReader (url.openStream (), charset); // This time, pass true to ignore the tag with its charset // attribute. new ParserDelegator ().parse (reader, callback, true); } catch (UnsupportedEncodingException e2) { System.err.println ("Invalid charset"); } catch (IOException e2) { System.err.println ("Input/Output problem"); e.printStackTrace (); } } catch (IOException e) { System.err.println ("Input/Output problem"); e.printStackTrace (); } } public static void saveImage (InputStream is, String filename) { FileOutputStream fos = null; try { fos = new FileOutputStream (filename); int bYte; while ((bYte = is.read ()) != -1) fos.write (bYte); } catch (IOException e) { System.err.println ("Unable to save stream to file"); } finally { if (fos != null) try { fos.close (); } catch (IOException e) { } } } } DE<
列表 4 使用
DE<r DE< 标识一个用于读取 HTML 文档的 DE<java.io.Reader DE< 对象。 DE<cb DE< 标识一个处理所解析的标记及其属性的 DE<javax.swing.text.html.HTMLEditorKit.ParserCallback DE< 对象。 DE<ignoreCharSet DE< 标识是否忽略文档的 DE<标记(如果存在)中的 DE<charset DE< 属性。 DE<
解析器在解析过程中调用了各种各样的
DE<t DE< 通过 DE<HTML.Tag DE< 对象对标记进行标识。 DE<a DE< 通过 DE<javax.swing.text.MutableAttributeSet DE< 对象标识标记内的属性。 DE<pos DE< 标识当前解析到的位置
现在您已经清楚地认识到
DE<uri being processed ... http://www.javajeff.mb.ca/common/logo.jpg uri being processed ... http://www.javajeff.mb.ca/common/logo.gif uri being processed ... http://www.javajeff.mb.ca/na/images/wom.jpg DE<
但是
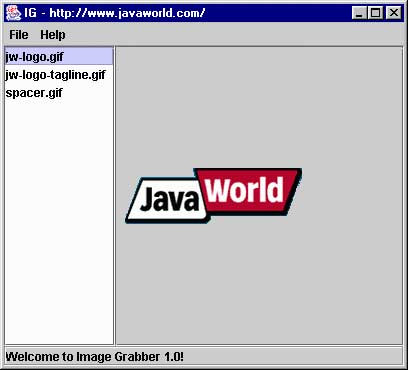
图 4 使用抓图程序的 GUI 方便地抓取和查看图像
结束语
此图像抓取程序将文章中介绍的技巧很好地结合在一起,但是还遗留了一些问题,关于这些问题的解决方法就当成家庭作业吧。问题 1:抓图程序下载图像,图像的标记需要指明相对 URL (例如,),但是无法下载指明绝对 URL 的图像(例如,)。
问题 2:抓图程序无法下载动态生成 的 src 属性的图像。作为例子,以下 标记的 src 属性是我最近在 JavaWorld 主页上发现的:src=”http://ad.doubleclick.net/ad/idg.us.nwf.jw_home/;abr=!ie;pos=top;sz=728×90;ptile=1;type=;ord=063423?”。
下载文章中使用的源代码:
http://www.javaworld.com/javaworld/jw-01-2007/games/jw-01-games.zip
您可以使用 Java Fun and Games 中的 DevSquare 在线开发工具来生成和运行 Applet。请阅读此入门指南: