java.util.Date和java.sql.Date的区别及应用实例。
java.util.Date 就是在除了SQL语句的情况下面使用
java.sql.Date 是针对SQL语句使用的,它只包含日期而没有时间部分
它都有getTime方法返回毫秒数,自然就可以直接构建
java.util.Date d = new java.util.Date(sqlDate.getTime());
…
——————————————————————————–[......]
java.util.Date和java.sql.Date的区别及应用实例。
java.util.Date 就是在除了SQL语句的情况下面使用
java.sql.Date 是针对SQL语句使用的,它只包含日期而没有时间部分
它都有getTime方法返回毫秒数,自然就可以直接构建
java.util.Date d = new java.util.Date(sqlDate.getTime());
…
——————————————————————————–[......]
NIO的ByteBuffer的几个方法的理解(对理解MINA的使用有帮助).
理解了这个。相信对于MINA的二次开发有相当大的帮助
import java.nio.ByteBuffer;
/****
*
* @author ADMIN
* 测试缓冲区的几个方法,对于理解缓冲区使用原理有相当大的帮助
*/
public class NioBufferTest {
public static void main(String args[]){
//分配字节缓冲区,分配10个
ByteBuffer bb=ByteBuffer.allocate(10);
//迭[......]
Java的基本特性. 1.若类变量没有初始化,并且直接在后面的代码中使用,那么系统会自动识别其数据类型,并且为他赋初值。而局部变量则不行,会直接报错。
2.访问修饰符:
public 工程
producted 本包+ 外包子类
默认 本包(默认叫做包权限修饰符)
private 本类(可以被继承,但是继承后无使用的权利)
———————————————————————————–[......]
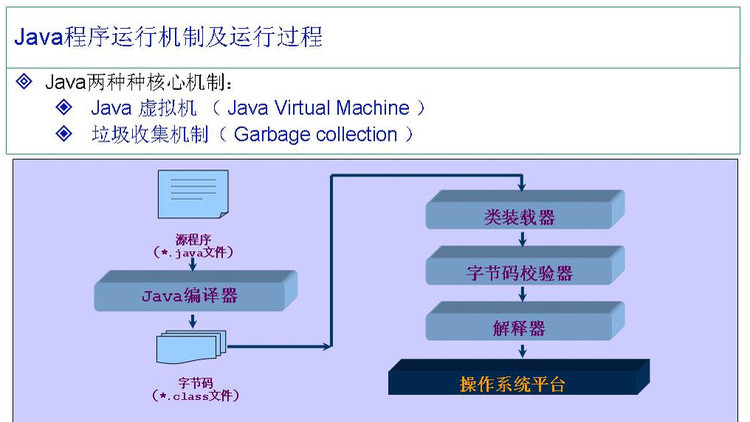
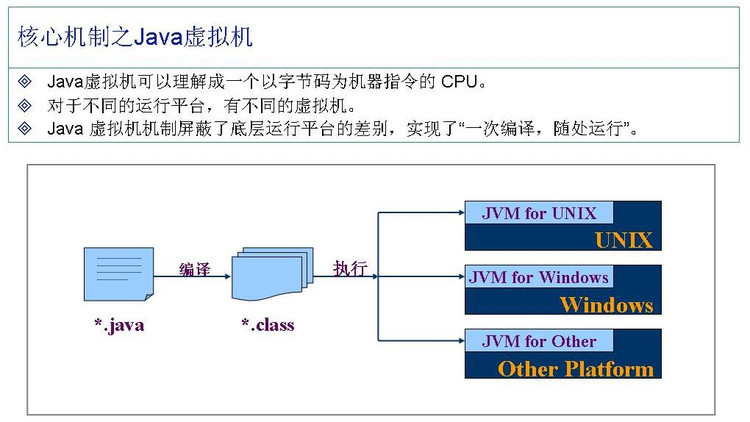
上图为Java的虚拟机机制
程序的执行过程:
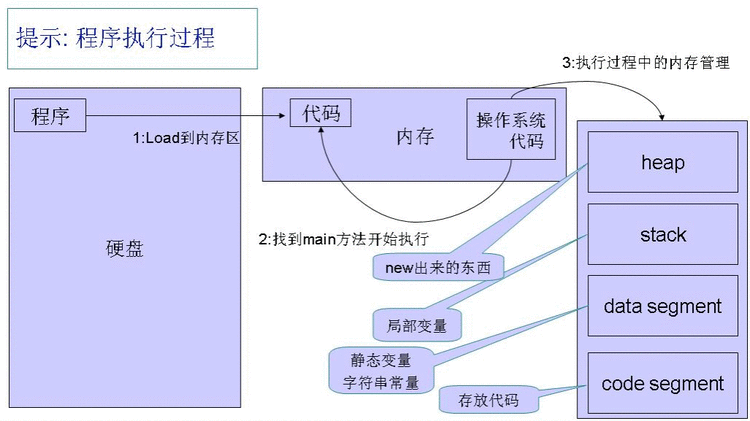
heap:堆 堆里面是动态分配内存的,只有在运行期间,才知道要划分多大的空间。
stack:栈
二、关系运算符
>,<,>=,<=,==,!=
三、逻辑运算符
!,&,|,^,~,>>,<<,>>>
四、赋值运算符
=
五、扩展赋值运算符
+=,-=,*[......]
对象和类
例子:
学生是一个类,
周杰伦是一个对象(对象可以看做是某一个类的具体实例)。
属性和类的成员变量是一回事。
—————————————————————————————————————————–
对象之间的关系:
关联关系 很弱的关系(一个方法需要传递一个参数)【用实线表示】
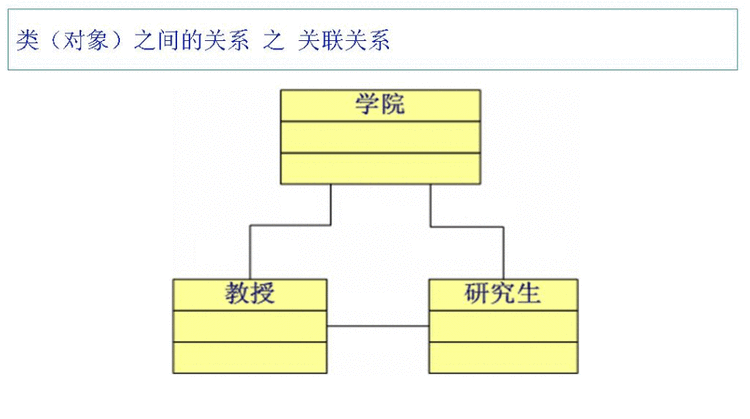
[......]
java内存分析.
下面开始面向对象的内存分析:
堆和栈的区别
堆存放的是不确定的大小值(只有在运行的时候才知道)。
栈的存取速度快 堆的存取数速度慢一些存储空间大。
除了基本类型剩余的都是引用类型。
基本类型
在栈中开辟一块新的空间,将值放在开辟好的栈当中。
先声明,再赋值,然后再使用。
声明:在内存中开辟一块新的空间。
初始化:给该空间一个初始的值。例如:int初始化值为0。
赋值:将值放在开辟好的内存当中。
引用类型
在栈里面保存的是一个对象的引用地址。真正的对象是保存在堆里面。
Person person = new Person();[......]
数组的排序
1.使用util包中的方法
Arrays.sort(); //参数是一个数组。
2.冒泡排序
int temp=0;
for (int i = 0; i < numInt.length-1; i++) {
for (int j = 0; j < numInt.length-i-1[......]
String separator = File.separator;
String path =
“dir1″+separator+”dir2″;
String filename = “Test.txt”;
File file = new
File(path,filename);
if (file.exists())
{
System.out.println(“文件保存的路径:”+file.getAbsolutePath());
System.out.println(“文件的大小:”+file.length());
}else
{
file.getParentFile([......]
Java容器类
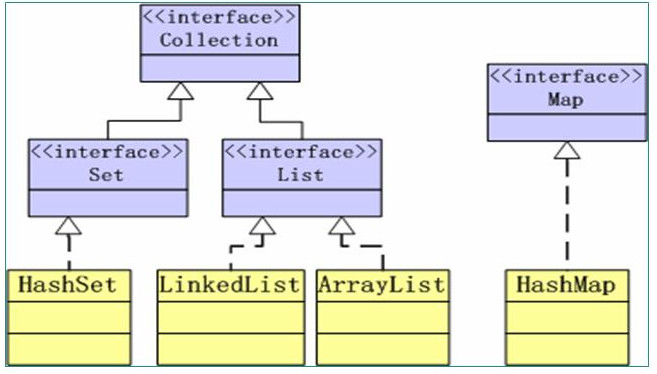
从上图可以看出容器类的结构。
Collection 接口定义了存取一组对象的方法,其子接口Set和List分别定义了存储方式。
这里的重复指其中的存储的值不可以有相同的。系统会自动调用(值所在)类的equal方法判断。 如需要去掉重复的几何元素,可以重写该方法。(重写了equal方法必须重写hashcode方法,目前不太明白为啥)
在Map存储键值对的时候, 键key[......]